
 University of Science and Technology of China
University of Science and Technology of ChinaI am currently a Ph.D. student in Computer Science at the University of Science and Technology of China (USTC), advised by Prof. Hong An. My research focuses on efficient graph deep learning systems and heterogeneous parallelism, with an emphasis on designing high performance system support for emerging graph learning workloads.
In particular, I work on scalable training and acceleration techniques for graph based workloads across modern parallel hardware. My recent research includes distributed acceleration for temporal graph neural networks, where I develop dependency aware multi GPU training frameworks to improve parallelism and reduce synchronization overhead while preserving model accuracy. I have also worked on efficient GPU sparse triangular solve, proposing graph based scheduling and sync free execution techniques to improve performance on irregular sparse workloads.
Education
-
University of Science and Technology of ChinaComputer Science and Technology
Ph.D. StudentSep. 2023 - present -
 Dalian University of TechnologyB.S. in Computer Science and TechnologySep. 2019 - Jul. 2023
Dalian University of TechnologyB.S. in Computer Science and TechnologySep. 2019 - Jul. 2023
Honors & Awards
-
First-Class Academic Scholarship2025, 2024, 2023
-
Outstanding Graduates2023
-
National Scholarship2022
-
Taoli Alumni Scholarship2023
Selected Publications (view all )
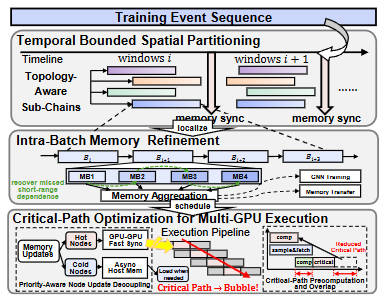
DepBloom: A Dependency-Aware Framework for Multi-GPU Temporal Graph Neural Networks Training
Yang Zhao, Yue Dai, Liang Qiao, et al.
Submitted to ASPLOS'27
We propose DepBloom to accelerate multi-GPU TGNN training with three techniques (1) temporally bounded spatial partitioning to reduce unnecessary cross-GPU synchronization and improve parallelism; (2) intra-batch memory refinement to recover missing short-range temporal dependencies inside enlarged batches; (3) critical-path optimization to prioritize urgent memory updates while deferring non-critical work during multi-GPU pipeline execution. Experimental results across representative models and diverse datasets show that DepBloom reduces multi-GPU training latency by 2.63$\times$ on average and up to 5.16$\times$ compared to state-of-the-art methods, while maintaining comparable or better model accuracy.
DepBloom: A Dependency-Aware Framework for Multi-GPU Temporal Graph Neural Networks Training
Yang Zhao, Yue Dai, Liang Qiao, et al.
Submitted to ASPLOS'27
We propose DepBloom to accelerate multi-GPU TGNN training with three techniques (1) temporally bounded spatial partitioning to reduce unnecessary cross-GPU synchronization and improve parallelism; (2) intra-batch memory refinement to recover missing short-range temporal dependencies inside enlarged batches; (3) critical-path optimization to prioritize urgent memory updates while deferring non-critical work during multi-GPU pipeline execution. Experimental results across representative models and diverse datasets show that DepBloom reduces multi-GPU training latency by 2.63$\times$ on average and up to 5.16$\times$ compared to state-of-the-art methods, while maintaining comparable or better model accuracy.
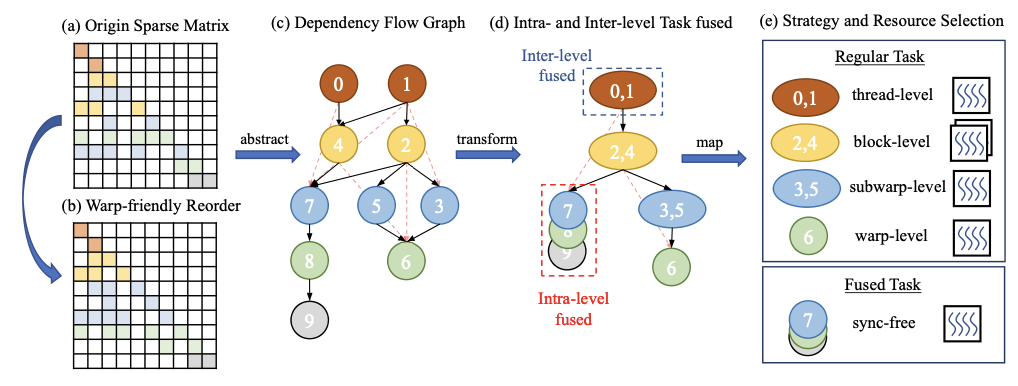
GSpTRSV: A Sparse Triangular Solve on GPUs Combining Graph and Sync-Free Method
Yang Zhao, J. Chen, L. Song, J. Cheng, H. An
Preprint
We present gSpTRSV, a GPU sparse triangular solve approach that combines graph-based scheduling with sync-free execution to improve parallelism and efficiency on irregular sparse workloads.
GSpTRSV: A Sparse Triangular Solve on GPUs Combining Graph and Sync-Free Method
Yang Zhao, J. Chen, L. Song, J. Cheng, H. An
Preprint
We present gSpTRSV, a GPU sparse triangular solve approach that combines graph-based scheduling with sync-free execution to improve parallelism and efficiency on irregular sparse workloads.